Inteligencia Artificial, cómo instalar una base de datos vectorial PostgreSQL en tu servidor con PG_Vector para tus LLM
La Inteligencia Artificial y los modelos LLM (Large Language Models) han venido para quedarse. Ahora nos parece normal poder hablar con una máquina y que esta nos entienda. Este boom explota de forma masiva en 2022. Antes parecía una tarea imposible.
Embbedings para los LLM, hablamos de vectores. ¿Qué son?
Los humanos sabemos leer texto y entender imágenes. Los ordenadores entienden de unos y ceros, teniendo que hablarles al más bajo nivel con lenguaje binario. Los LLM para poder entender el lenguaje natural usan vectores y cuanto más cerca esté un vector de otro mayor parecido semántico tendrá.
Para calcular la cercanía se usa la similitud de coseno, álgebra básica.
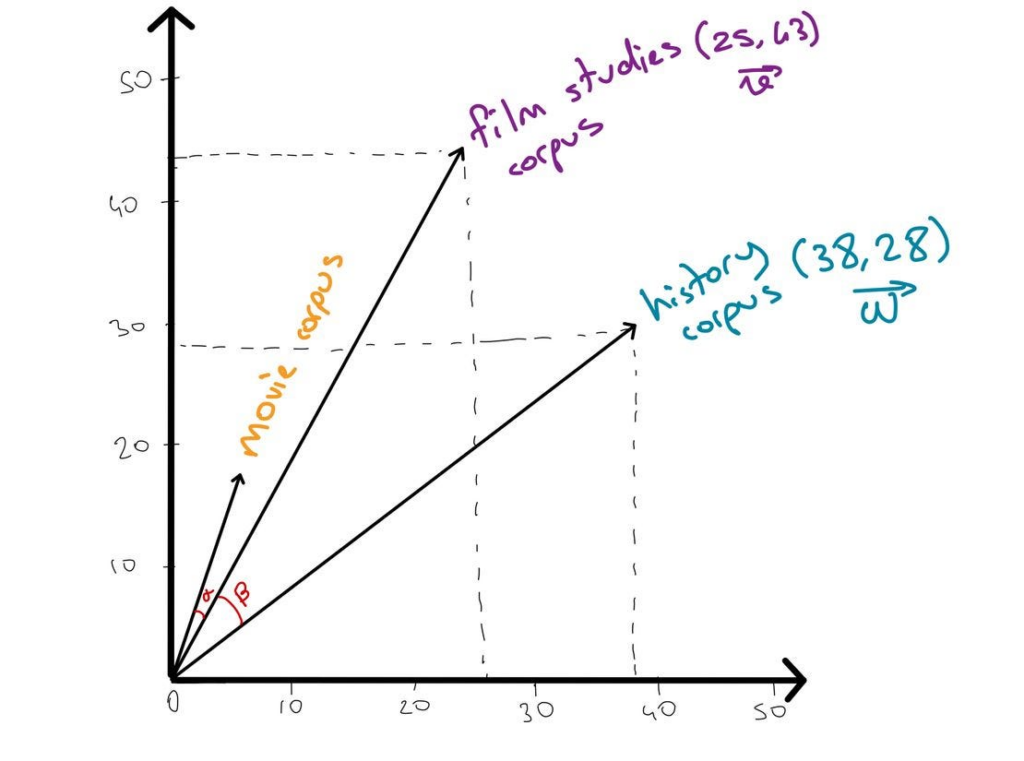
Imagina que cada palabra o frase que conocemos puede ser representada por un punto en un mapa. Este mapa no es como los que estamos acostumbrados a ver, sino un mapa muy especial donde las distancias entre los puntos no hablan de kilómetros, sino de similitudes de significado o contexto. En este mapa, palabras o frases con significados similares están más cerca unas de otras. Esto es, en esencia, lo que hace un embedding: convierte texto en puntos en un mapa de alta dimensionalidad, lo que nos permite trabajar con ellos matemáticamente.
Aquí puedes ver una representación gráfica interactiva de una base de datos vectorial de palabras del lenguage en inglés y ver cómo unos términos está más cerca unos de otros por parecido semántico:
https://projector.tensorflow.org/
Se hace un representación en tres dimensiones que lo que como humanos podemos entender pero los LLM están ya a fecha de publicación de este post trabajando con cosenos de más de 8.000 dimensiones para poder comprender la dificultad del lenguage.

*Imagen Creada con OpenAI: Prompt Imagen: dibujo que representa a un robot en modo cómic, calculando la distancia entre varios vectores con una regla, en un entorno colorido y moderno que simboliza una base de datos vectorial. Este diseño incorpora elementos futuristas y un toque de diversión, destacando el proceso matemático de medir similitudes en un espacio abstracto.
¿Cómo funciona por debajo los Embeddings de las bases de datos vectoriales?
Los embeddings son representaciones vectoriales de alta dimensionalidad que capturan la semántica de las palabras, frases, o incluso documentos enteros. Se generan utilizando modelos de lenguaje profundo, que han sido entrenados en enormes cantidades de conocimiento de texto. Estos modelos entienden el contexto y la relación semántica entre palabras al observar cómo se usan en diferentes contextos, permitiéndoles generar vectores donde la distancia geométrica refleja la similitud semántica.
Al aplicar embeddings a la información de una empresa, transformamos textos en vectores en un espacio de alta dimensionalidad. Esto se hace procesando el texto (descripciones de productos, servicios, FAQs, etc.) a través de un modelo de embeddings, que asigna a cada pieza de texto un vector único. Estos vectores se almacenan luego en una base de datos vectorial.
Base de Datos Vectorial: PostgreSQL con pg_vector
Para manejar eficientemente los vectores generados por los embeddings, utilizamos PostgreSQL con la extensión pgvector. Esta extensión está diseñada para almacenar y realizar operaciones eficientes con vectores, como la búsqueda por similitud. La búsqueda se basa en calcular la distancia del coseno entre vectores, que mide la similitud coseno entre dos vectores, proporcionando una forma efectiva de encontrar el contenido más relevante en respuesta a una consulta vectorizada del usuario.
Esta es una de las opciones para tener tu base de datos bajo tu control en un servidor propio pero existen más alternativas como Meilisearch y poder juntar los mundos de semántica y búsqueda indexada facetada, pero a día de hoy está en fase Experimental. Hay varios SaaS conocidos como Pinecone u otros que también te pueden dar solución como servicio.
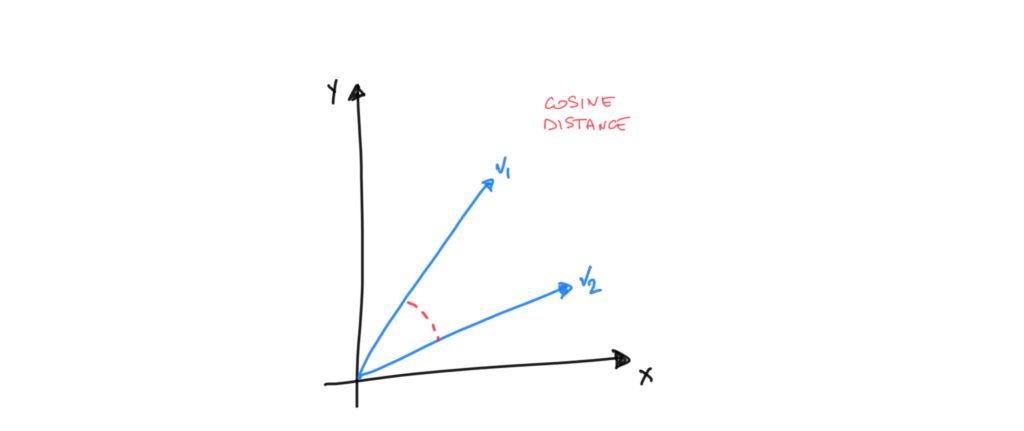
Cálculo de la Similitud del Coseno
La similitud del coseno entre dos vectores se calcula como el coseno del ángulo entre estos dos vectores. Valores cercanos a 1 indican una gran similitud, mientras que valores cercanos a 0 indican baja similitud. Esta métrica es especialmente útil en espacios de alta dimensionalidad para medir cómo de «cerca» está un término de otro.
¿Qué podemos hacer con los Embeddings?
Una vez tenemos toda la información vectorizada podemos explotarla de diferentes maneras:
✅ Hacer un buscador semántico por ejemplo para un comercio electrónico entiendo todos los sinónimos o expresiones sin estar escritas en el texto del producto, las entiende por contexto, por lo tanto un cliente que desconoce el catálogo podría hacer la búsqueda de Borgoña que se puede referir a color, región, o DO de vinos o decir que se va a la nieve y poder ofrecerle gorros y guantes.
✅ Clasificación y clusterización por ejemplo para perfilar usuarios y hacer remarketing
✅ Recomendaciones para productos cruzados, up-selling, etc.
✅ Dotar de conocimiento específico a un LLM para especializar y acotar la respuesta al conocimiento de tu empresa u organización. Con esto podemos hacer Chatbots asistenciales que den soporte a clientes, pacientes, trabajadores y empleados, alumnos, profesores…
✅ Análisis de sentimientos y de la voz del cliente
✅ Forecast y predicciones de ventas para preparar los inventarios ante cambios en la demanda estacional…
Pasos para Instalar una Base de datos Vectorial en tu Ubuntu Server
👉 Primero de todo debes instalar postgresql y todos los paquetes necesarios para su funcionamiento, si ya lo tenías instalado te valdrá con solo añadir el último paquete postgresql-server-dev-16:
sudo apt update
sudo apt install postgresql postgresql-contrib libpq-dev
apt install postgresql-server-dev-16👉 Instalar el plugin de pg_vector desarrollado por postgresql. Dota a la base de daots de las funciones pra poder calcular la similitud de coseno:
cd /tmp
git clone --branch v0.7.4 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # tal vez necesites sudohttps://github.com/pgvector/pgvector
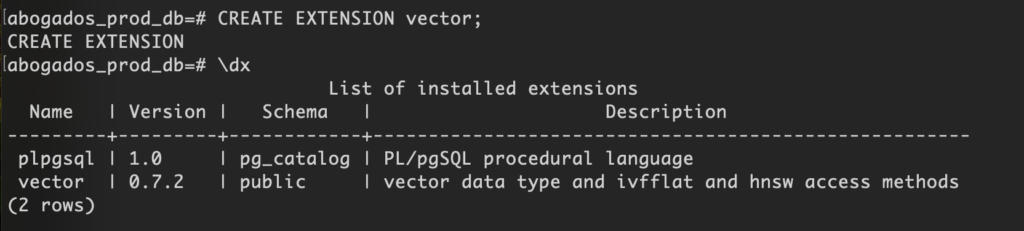
👉 Activar pg_vector en tu base de datos, esto debes hacerlo en cada DB:
Primero Entrar a la DB
psql -U usuarioDeTuDBpsql -U usuarioDeTuDB -d nombreDeTuDBSegundo ejecuta el SQL para crear la extensión y que estén disponibles las funcionalidades vectoriales
CREATE EXTENSION vector;👉 Comprueba que todo ha salido bien con \dx